Overview
SoVisu+ Harvester is a generic tool designed for harvesting bibliographic references from various sources and to convert them into a common standardized format.
It is intended to provide a unified interface to the various scholarly publication databases and repositories that are used by an institutional research information system or a bibliographic data management system.
Project repository
Source code is available on Github :
Note
SoVisu+ Harvester belongs to the SoVisu+ project, which aims to provide a set of robust and scalable components to build research information management systems. But it may also be used as a standalone tool or integrated to a completely different system.
Warning
SoVisu+ Harvester does not control identifiers matching : It is intended for use in institutions that have already created and actively maintain a repository of matched identifiers for authors, structures and research projects. It also does not perform deduplication of references, as this functionality will be implemented in a separate component.
Overall operating mode
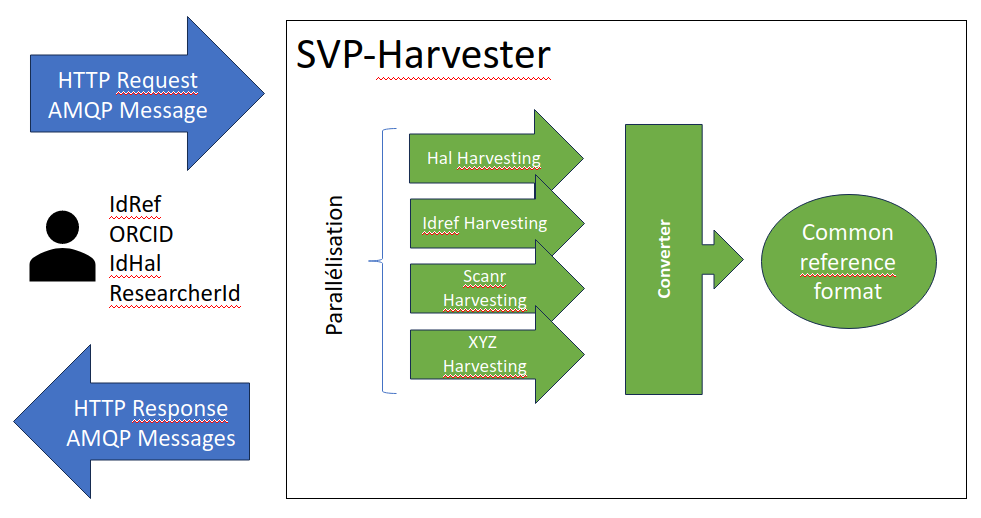
The SoVisu+ Harvester is designed to receive requests containing a list of identifiers for a so-called “research entity” (which can be an author, research structure, research institution or research project) and to return a list of bibliographic references encoded with a common model that are associated with the research entity.
Key Features
🧱 Extensibility
SoVisu+ Harvester serves as a runner for a group of harvesters, each of which is defined with specific parameters in a configuration file. These harvesters are responsible for retrieving data from distinct sources and converting it into a uniform format.
🆔 Flexible identifiers management
The tool performs harvestings on behalf of various kinds of entities (wich may be persons, research structures, laboratories of projects). For each type of entity, it accepts a wide range of identifiers (such as IdRef, ORCID, IdHal) with which each harvester will perform his task as best as he can in a loosely coupled way.
⚙️ Parallel Processing
To optimize performance, the harvesters are run concurrently. The results can be delivered in real-time or as a single batch upon completion of the process, with options for both synchronous and asynchronous modes.
🥫 Standardized Output Format
The harvested data is converted into a common format, aligning with the SciencePlus data model. This model is based on widely accepted ontologies in the field, such as Dublin Core, Bibo, Vivo, and more.
🔌 Various integration modes
The microservice is intended to be integrated in a bibliographic data management system or in a research information management system. It is compatible with service oriented architecture (throught REST API) as well as with message oriented architecture (throught AMQP protocol and RabbitMq).
👁 Harvesting monitoring
The database keeps track of all the harvestings and the errors that may arise during the process. To prevent nightly harvesting failures from becoming a system weakness, the harvesting history is readily accessible via a web interface, harvesting results or errors can be notified.
🔗 Entity Dereferencing
SoVisu+ Harvester enhances data quality through entity dereferencing. It uses unique identifiers (like IdRef URI, Wikidata ID, ROR ID, etc.) provided by entities to fetch and verify information from various repositories. For performance reasons, some of the authoritative sources are represented by a proxy or their data stored in a local cache. E.g. see SVP JEL Proxy Container
Functional scope limitations
Warning
1. No identifiers matching: By design, it is up to the system client to perform identifier matching for each submitted entity before sending it to the harvester. Identifier matching is governed by complex rules that differ depending on the type of identifier and the type of entity (e.g., authenticated identifiers like ORCID or identifiers managed by librarians like IdRef). For this reason, the harvester does not perform any matching and always considers the submitted matches as valid. The so-called “entity resolution” component is intended to maintain a consistent harvesting history even in cases where matches change over time.
Warning
2. No deduplication: Reference deduplication is a complex process that can be implemented via several approaches (rules engine or probabilistic artificial intelligence). The present tool does not perform any deduplication. It is up to the system client to perform deduplication on the harvested references.